

假如我们使用分布式缓存★★■,Redis 天然支持批量查询的命令 ★◆★★■,比如 mget ,hmget 。
机制是 80x86 内存管理机制的第二种机制,分段机制用于把虚拟地址转换为线性地址,而

在单片机程序中的使用是非常有效的,非常有用的★■★★★,关于这个话题在此专门开一文章来
MyBatis是一个开源的Java持久层框架,它与其他ORM(对象关系映射)框架相比,具有更加灵活和高性能的特点◆■。MyBatis提供了两种
次阅读 --
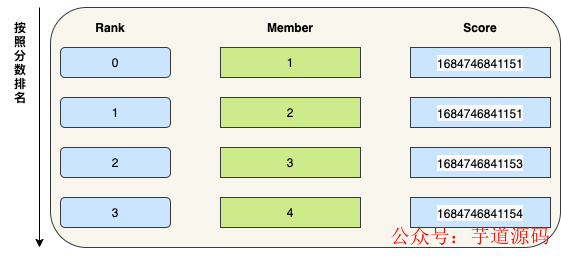
我们使用推模式将每一条动态 ID 存储在 Redis ZSet 数据结构中 。Redis ZSet 是一种类型为有序集合的数据结构,它由多个有序的唯一的字符串元素组成,每个元素都关联着一个浮点数分值。
2◆★■◆◆、使用 Redis 的 keys 找到该业务的分页缓存◆◆,执行删除指令。但 keys 命令对性能影响很大◆★■,会导致 Redis 很大的延迟 。
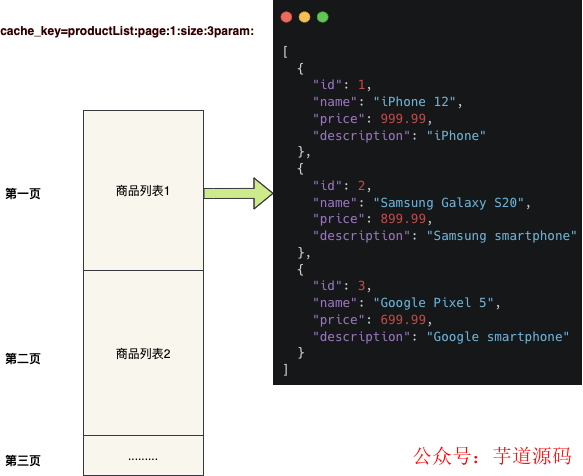
这种方案的优点是工程简单,性能也快★★,但是有一个明显的缺陷基因★■★:列表缓存的颗粒度非常大◆◆■◆。
机制 /
需求时,一般会用limit实现,但是当偏移量特别大的时候■★★,查询效率就变得低下◆★■★◆。本文将分四个方案,讨论如何优化MySQL百万数据的深
许多web服务需要对数十亿个小对象实现快速访问,而每个小对象只有几百个字节。为了实现这一点同时考虑实际生产效益★■◆■,
次阅读 --

次阅读 --
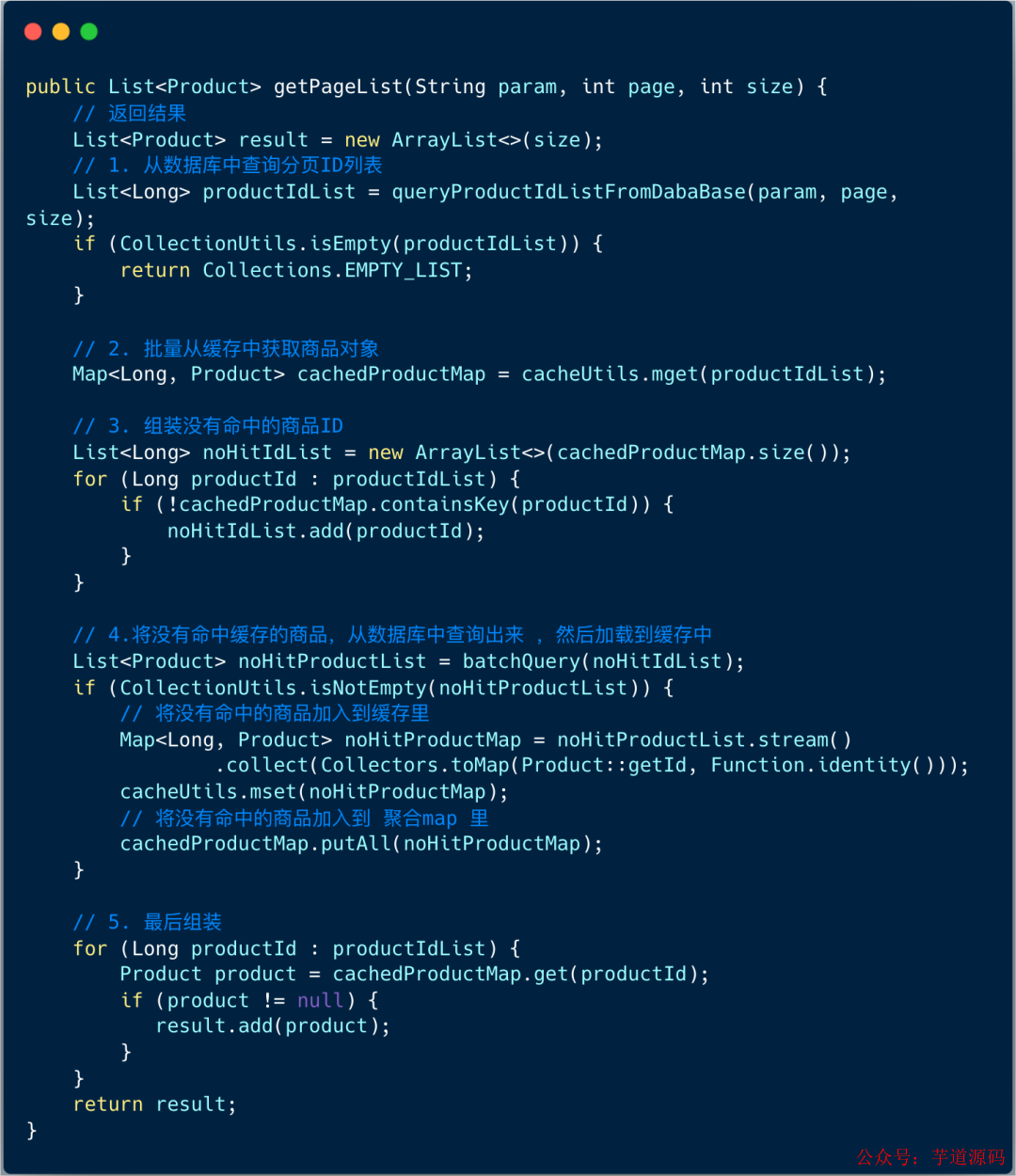
我们先查询出商品分页对象ID列表,然后为每一个商品对象创建缓存 ◆★, 通过商品ID和商品对象缓存聚合成列表返回给前端★◆。
次阅读 --
在单片机程序中的使用是非常有效的◆■★◆★,非常有用的★■,关于这个话题在此专门开一文章来
次阅读 --
若缓存对象结构简单,使用 mget ◆■◆■◆、hmget 命令;若结构复杂,可以考虑使用 pipleline,Lua 脚本模式 。笔者选择的批量方案是 Redis 的 pipleline 功能◆■。
的读写非常快■◆,没有网络开销。但各应用或集群的各节点都需要维护自己的单独
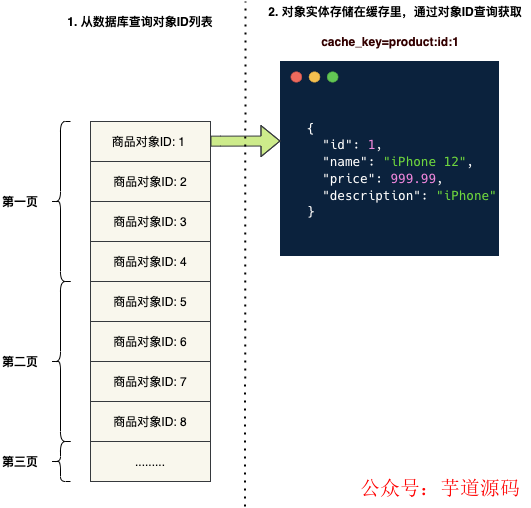
当前方案里,缓存都有命中的情况下,经过两次网络IO ,第一次数据库查询 IO ◆◆◆,第二次 Redis 查询 IO ◆■★, 性能都会比较好。
生产环境使用 keys 命令比较危险,发生事故的几率高,非常不推荐使用。
为什么用FatFS在SD卡创建文件,在单片机上读写正常,用读卡器插到电脑上就什么都没有
设计 /
查询出动态 ID 列表后★◆★,还需要缓存每个动态对象条目★◆■■■,动态对象包含了详情,评论,点赞■◆◆★★■,收藏这些功能数据 ,我们需要为这些数据提供单独做缓存配置。
文章出处★★◆■:【微信号■■★◆:芋道源码,微信公众号★■■:芋道源码】欢迎添加关注!文章转载请注明出处★■■■■★。
次阅读 --

次阅读 --
ZREVRANGE 是 Redis 中用于有序集合(sorted set)的命令之一◆◆,它用于按照成员的分数从大到小返回有序集合中的指定范围的成员。
给ADUM4223 增加信号驱动15V电压就不正常◆■, 波动很大会被烧是什么情况?
次阅读 --
笔者曾经重构过类似朋友圈的服务,进入班级页面 ,瀑布流的形式展示班级成员的所有动态。
次阅读 --
传递动态 ID 列表参数★■◆,通过 Redis 的 pipleline 功能从缓存中批量获取动态的详情,评论,点赞,收藏这些功能数据 ,组装成列表 。
框能够分100页显示,每页显示100条数据,且能够利用数值控件进行翻页■◆★■★■。
次阅读 --
精髓在于:搜索的分页结果只包含业务对象 ID ★★■,对象的详细资料需要从缓存 + MySQL 中获取。
STM32CUBEMX(13)--SPI,W25Q128外部Flash移植
这是最简单易懂的方案,我们按照不同的分页条件查询出结果后,直接缓存分页结果 。
因为缓存中可能因为过期或者其他原因导致缓存没有命中的情况,所以我们需要找到哪些商品没有在缓存里。
次阅读 --
次阅读 --
★★◆◆■◆”查询对象ID列表,再缓存每个对象条目◆■“ 这个方案比较灵活◆■◆■,当我们查询对象ID列表,可以不限于数据库◆◆■■★,还可以是搜索引擎◆★■◆★,Redis 等等。
用于驾驶员监控系统的NIR LED驱动器套件STR-DMS-NCV7694-GEVK系列数据手册
次阅读 --
次阅读 --
次阅读 --
然后这些未命中的商品信息存储到缓存里 , 使用 Redis 的 mset 命令■◆★■。
在STM32单片机的应用 /








